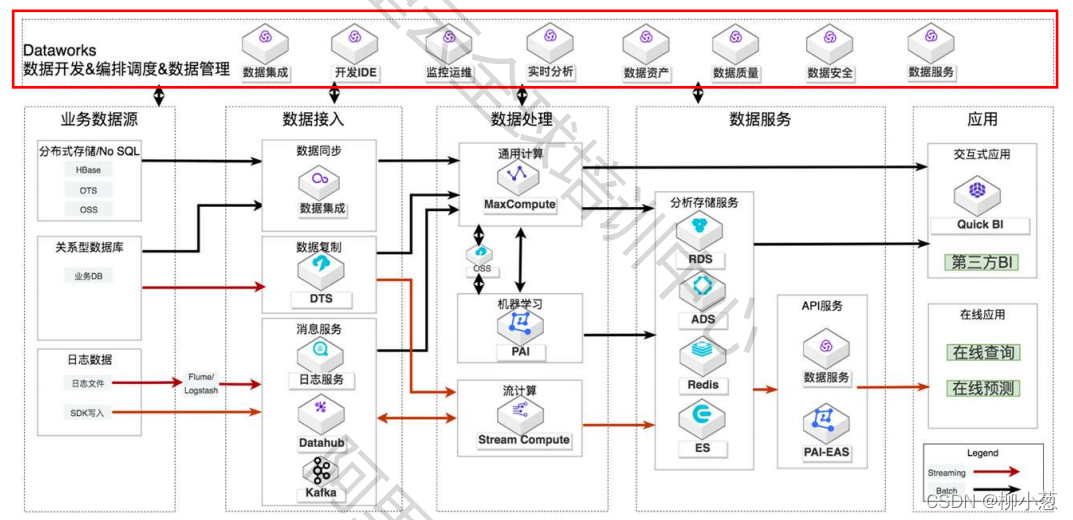
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
前置概念
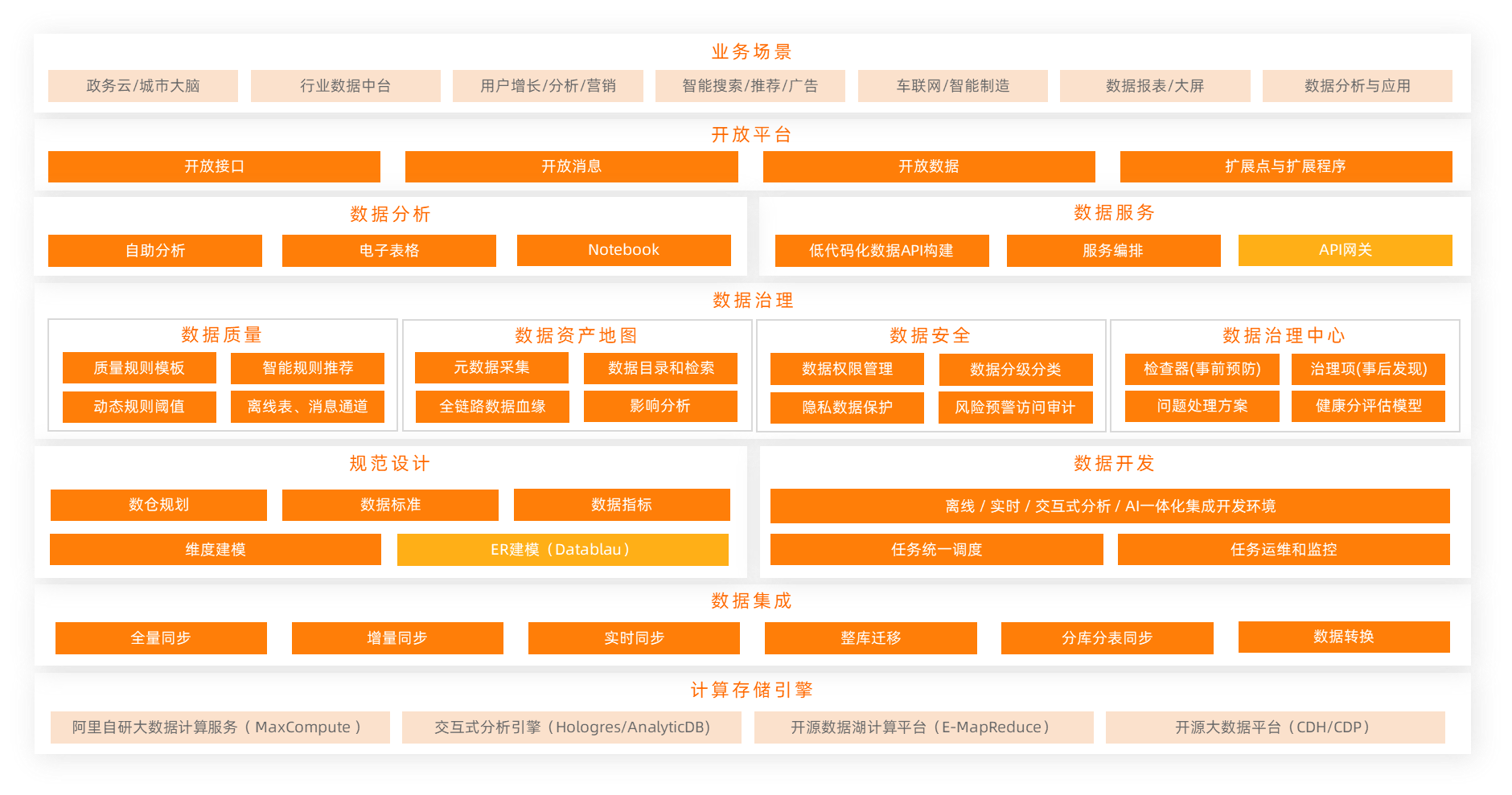
产品架构
DataWorks通过**智能数据建模、全域数据集成、高效数据生产**、主动数据治理、全面数据安全、数据分析服务六大全链路数据治理的能力,帮助企业治理内部不断上涨的“数据悬河”,释放企业的数据生产力。

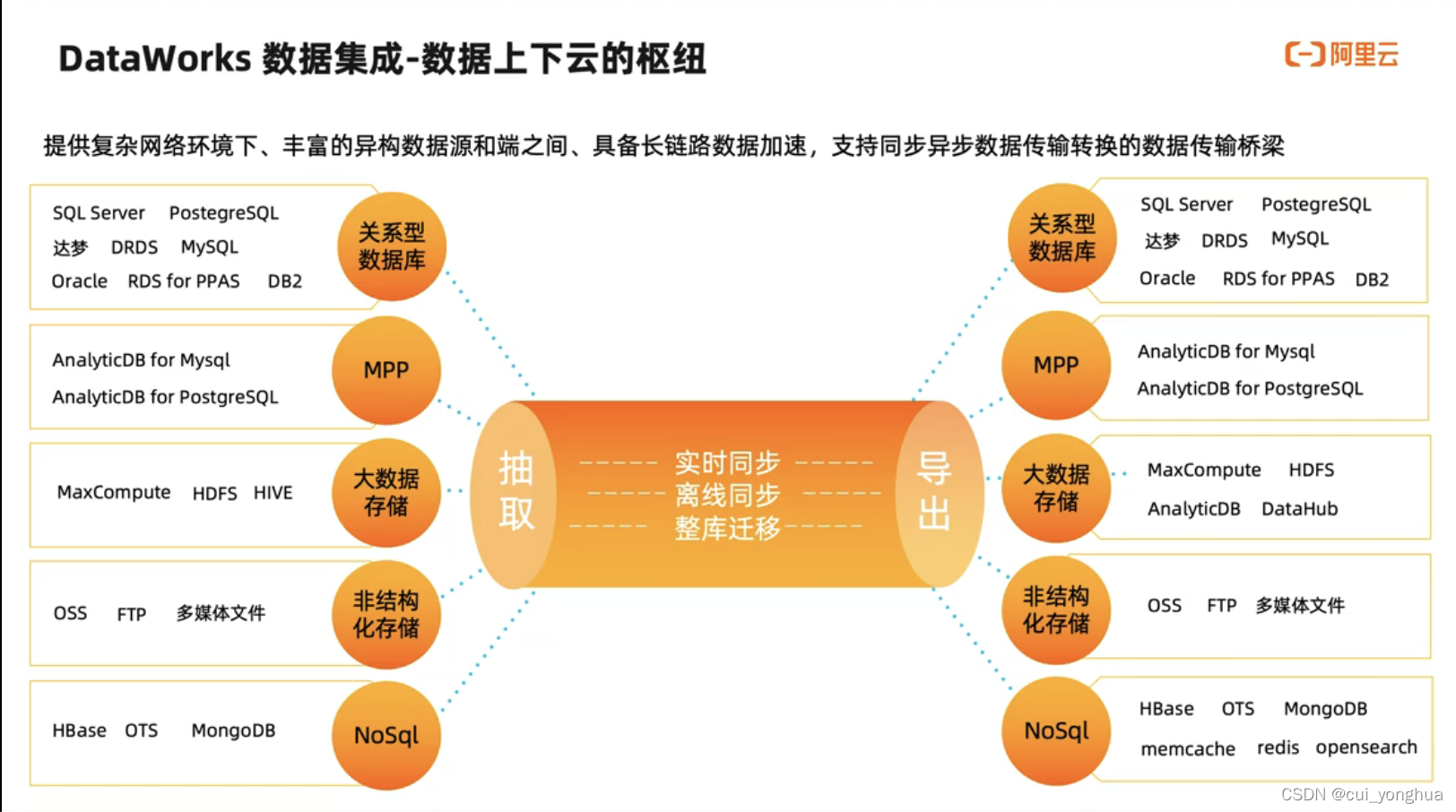
数据集成
DataWorks的数据集成功能模块是稳定高效、弹性伸缩的数据同步平台,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动及同步能力。
功能概述
DataWorks的数据集成支持离线同步、实时同步,以及离线和实时一体化的全增量同步。其中:
离线同步场景下,支持设置离线同步任务的调度周期。
支持关系型数据库、数仓、非关系型数据库、文件存储、消息队列等近50多种不同异构数据源之间的数据同步。
支持在各类复杂网络环境下,连通数据源的网络解决方案,无论数据源在公网、IDC还是VPC内,均可使用DataWorks数据集成实现网络连通。
支持安全控制与运维监控,保障数据同步的安全、可控。
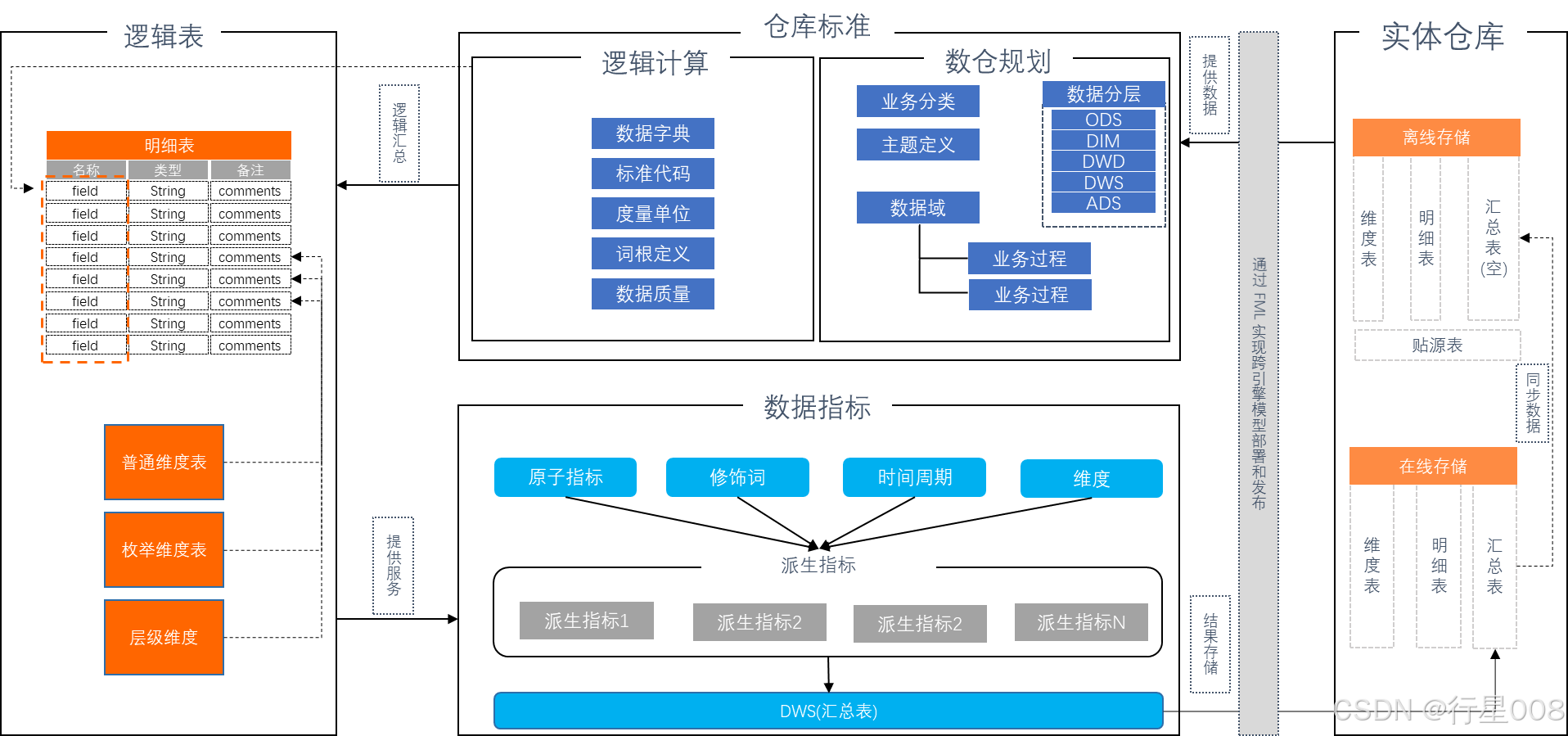
规范设计(数据建模)
数仓规划、数据标准、数据指标、维度建模、ER建模(Datablau)智能数据建模是阿里云DataWorks自主研发的智能数据建模产品,沉淀了阿里巴巴十多年来数仓建模方法论的最佳实践,包含数仓规划、数据标准、维度建模及数据指标四大模块,帮助企业在搭建数据中台、数据集市建设过程中提升建模及逆向建模的能力,并通过数据建模快速构建企业数据资产。
功能概述
智能数据建模产品包含数仓规划、数据标准、维度建模、数据指标四大产品模块。
数仓规划:数仓规划支持数仓分层、数据域、数据集市等的规划,支持设置模型设计空间,不同部门可共享一套数据标准和数据模型。
数据标准:数据标准字段标准、标准代码、度量单位、命名词典的定义,支持标准代码自动生成质量规则,落标检查不再难。
维度建模:维度建模支持逆向建模,解决现有数仓的建模冷启动难题,支持可视化数仓维度建模,支持通过Excel文件导入模型和通过FML(一种类SQL的DSL)快速构建模型,支持与数据开发DataStudio无缝打通,自动生成ETL代码。
数据指标:数据指标支持原子指标、派生指标的定义与构建,与维度建模无缝打通,可根据原子指标和不同维度批量创建派生指标。
核心技术与架构
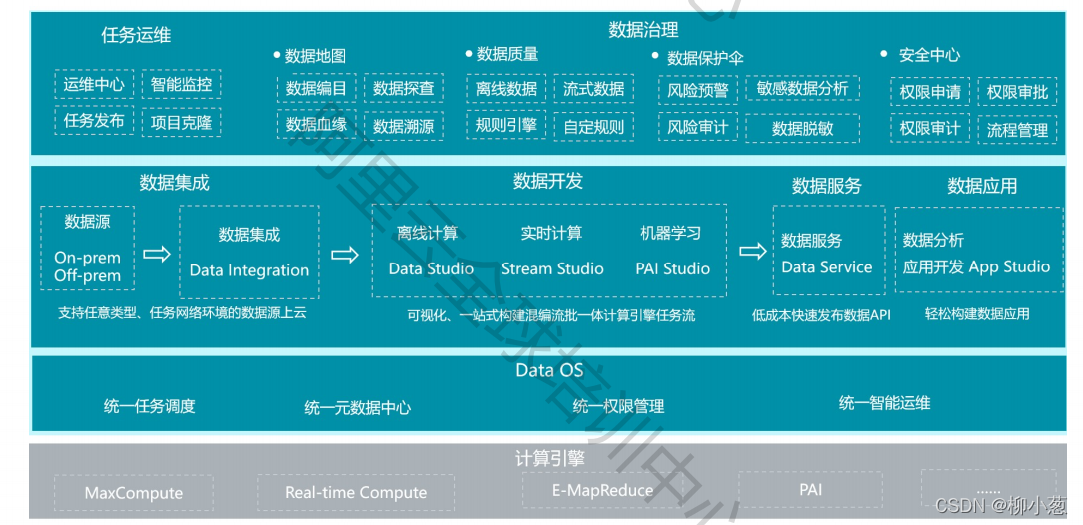
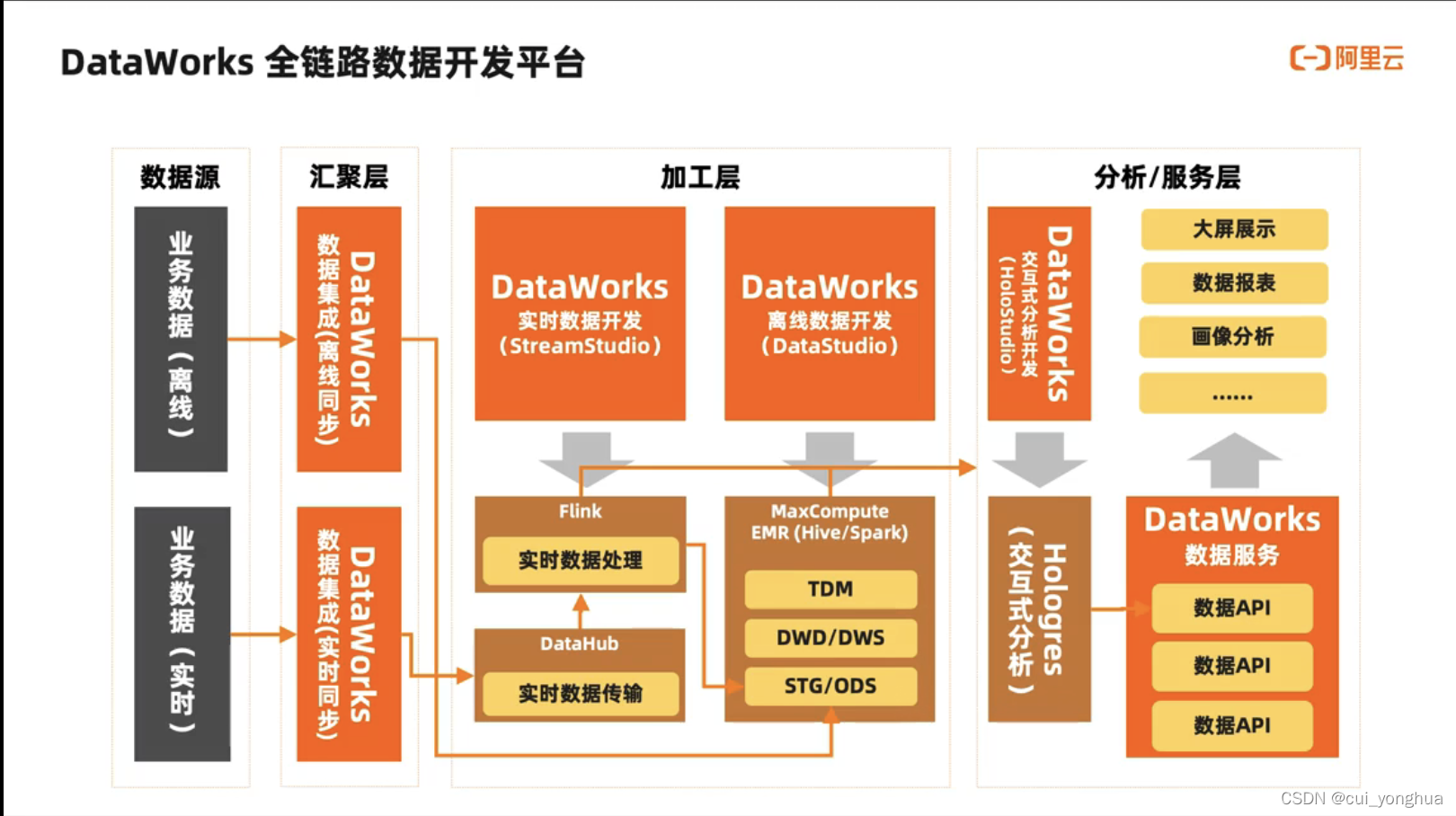
数据开发(DataStudio)
离线/实时/交互式分析/AI一体化集成开发环境、任务统一调度、任务运维和监控DataWorks的**数据开发(DataStudio)**是数据加工的开发平台,运维中心是智能运维平台,基于这两个功能模块,您可以在DataWorks上规范、高效地构建和运维数据开发工作流。
功能概述
DataWorks的数据开发的亮点功能如下。
DataStudio支持MaxCompute、EMR、CDH、Hologres、AnalyticDB、Clickhouse等多种计算引擎,支持在统一的平台上进行各类引擎任务的开发、测试、发布和运维等操作。
DataStudio支持智能编辑器、可视化依赖编排,调度能力经过阿里集团内调度任务、复杂业务依赖的反复验证。
DataStudio提供隔离的开发和生产环境,结合版本管理、代码评审、冒烟测试、发布管控、操作审计等配套功能,帮助企业规范地完成数据开发。
运维中心支持数据时效性保障、任务诊断、影响分析、自动运维、移动运维等功能。
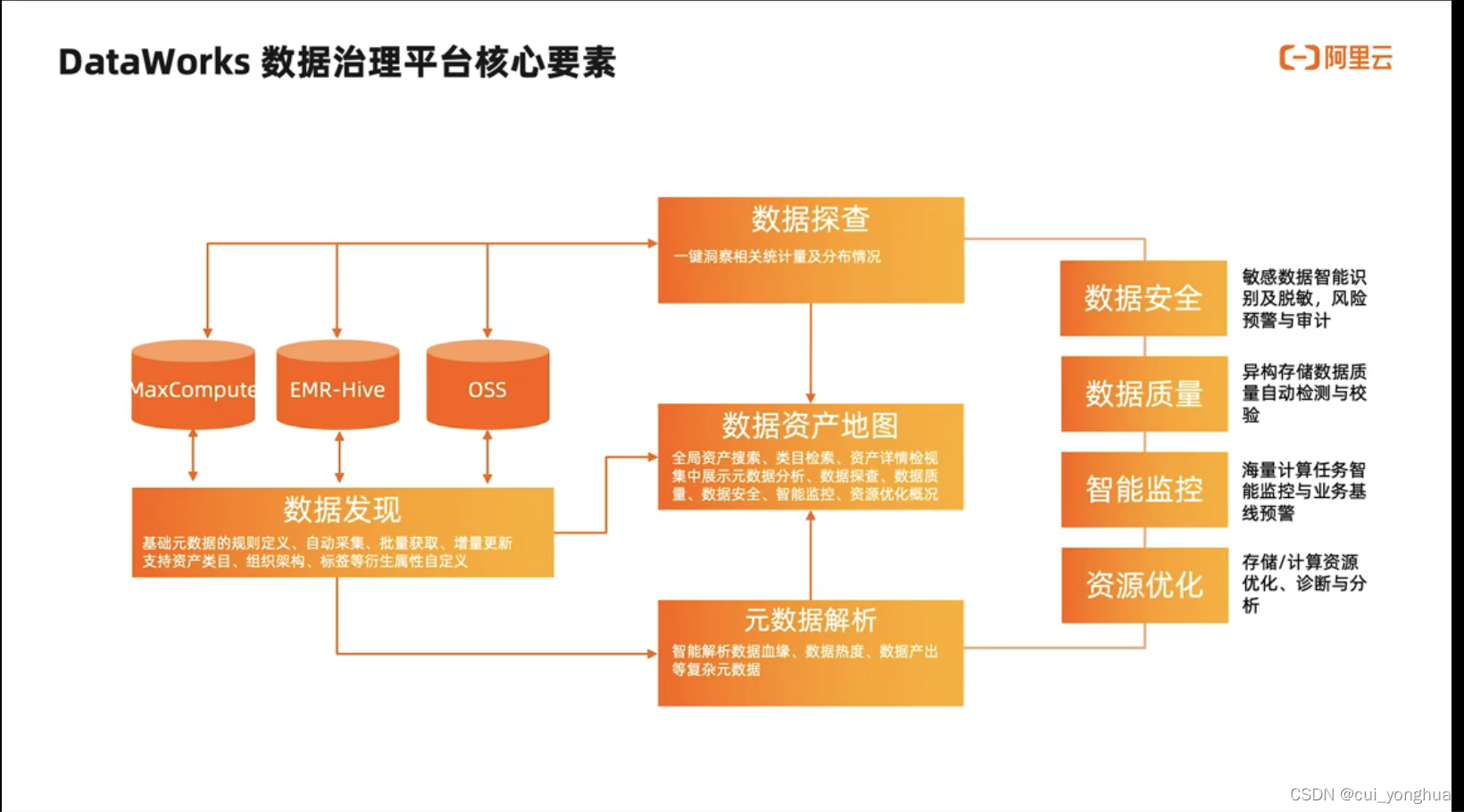
数据治理
数据质量、数据资产地图、数据安全、数据治理中心数据地图
DataWorks的数据地图功能可以帮助您实现对数据的统一管理和血缘的跟踪。数据地图以数据搜索为基础,提供表使用说明、数据类目、数据血缘、字段血缘等工具,帮助数据表的使用者和拥有者更好地管理数据、协作开发。
功能概述
数据地图是在元数据基础上提供的企业数据目录管理模块,涵盖全局数据检索、元数据详情查看、数据预览、数据血缘和数据类目管理等功能。数据地图可以帮助您更好地查找、理解和使用数据。
数据质量
DataWorks的全流程数据质量监控功能为您提供35种预设表级别、字段级别和自定义的监控模板。数据质量帮助您第一时间感知到源端数据的变更与ETL(Extract Transformation Load)中产生的脏数据,自动拦截问题任务,有效阻断脏数据向下游蔓延。
功能概述
数据质量以数据集(DataSet)为监控对象,支持监控MaxCompute数据表和DataHub实时数据流。当离线MaxCompute数据发生变化时,数据质量会对数据进行校验,并阻塞生产链路,以避免问题数据污染扩散。同时,数据质量提供历史校验结果的管理,以便您对数据质量进行分析和定级。
数据质量可以解决如下问题:
- 数据库频繁变更问题
- 业务频繁变化问题
- 数据定义问题
- 业务系统的脏数据问题
- 系统交互导致质量问题
- 数据订正引发的问题
- 数据仓库自身导致的质量问题
数据资产治理
数据资产治理是统一资产治理系统,针对多个治理领域,通过数据领域规则沉淀、自动识别资产待优化问题项、覆盖事后及事前的治理优化策略等方式,帮助用户主动式、体系化完成数据治理工作。
功能概述
数据资产治理(原数据治理中心)可根据预先配置的治理计划,自动发现平台使用过程中数据存储、任务计算、代码开发、数据质量及安全等维度存在的问题,并通过健康分量化评估,从全局、工作空间、个人等多个视角,以治理报告及排行榜呈现治理成果,帮助您高效达成治理目标。同时,还提供业务资产管理、资产分析、任务资源消耗明细、费用预估等功能,帮助您有效掌握各类资源的使用详情。
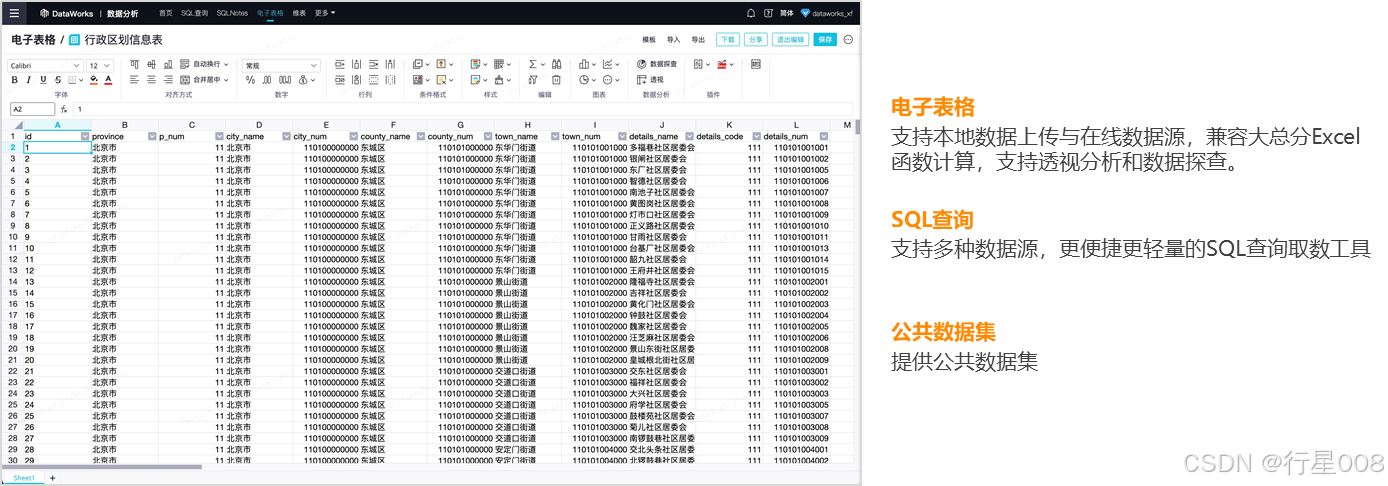
数据分析
DataWorks提供的数据分析平台,可以流畅地进行数据处理、分析、加工及可视化操作。在数据分析板块中,您不仅可以在线洞察数据,还可以编辑和共享数据.
功能概述
数据分析支持基于个人视角的数据上传、公共数据集、表搜索与收藏、在线SQL取数、SQL文件共享、SQL查询结果下载及用电子表格进行大屏幕数据查看等产品功能。
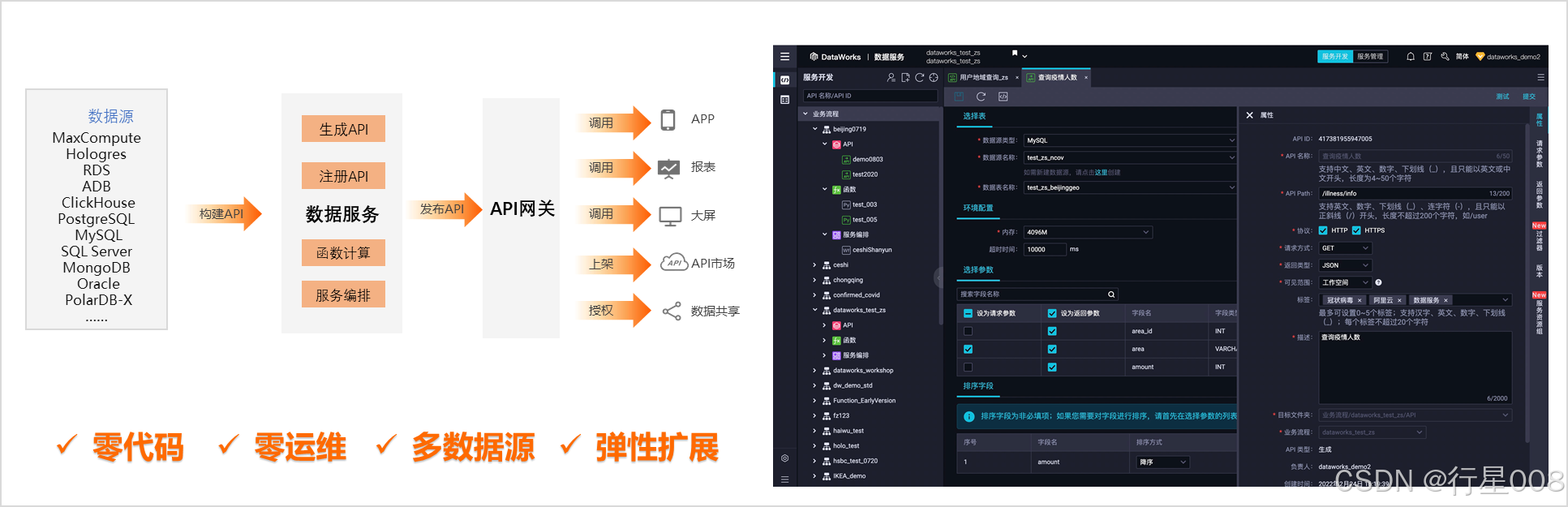
数据服务
DataWorks的数据服务功能模块是灵活轻量、安全稳定的数据API构建平台,旨在为企业提供全面的数据共享能力,帮助用户从发布审批、授权管控、调用计量、资源隔离等方面实现数据价值输出及共享开放。
功能概述
作为数据仓库与上层应用系统间的“桥梁”,DataWorks数据服务为企业搭建统一的服务总线,帮助企业统一创建及管理对内、对外的API服务,解决数仓、数据库与数据应用间的“最后一公里”,加速数据的流动和共享。
- 数据服务支持通过零代码或自助SQL的双模式,将各类数据源下的数据表生成数据API,同时支持函数计算来辅助加工API的请求参数及返回结果。
- 数据服务采用Serverless架构,用户无需关心运行环境等基础设施,即可将API服务一键发布至API网关。
应用场景
构建数据仓库
DataWorks具有通过可视化方式实现数据开发、治理全流程相关的核心能力,在此介绍DataWorks在构建云上大数据仓库和构建智能实时数据仓库两个典型应用场景下的应用示例。
构建云上大数据仓库
本场景推荐的架构如下。

适用行业:全行业适用。
方案优势:阿里巴巴大数据最佳实践,高性能、低成本、Serverless服务,免运维、全托管模式,让企业的大数据研发人员更聚焦在业务数据的开发、生产、治理。
产品组合:MaxCompute + Flink + DataWorks。
场景说明
用户数据来源丰富,包括来自云端的数据、外部数据源,数据统一沉淀,完成数据清洗、建模。
用户的应用场景复杂,对非结构化的语音、自然语言文本进行语音识别、语义分析、情感分析等,同时融合结构化数据搭建企业级的数据管理平台,并且计算和存储成本最低。
平台支撑多种形式的应用,包括使用机器学习算法进行复杂数据分析、使用BI报表进行图表展现、使用可视化产品进行大屏展示、使用其他自定义的方式消费数据。
构建智能实时数据仓库
本场景推荐的架构如下。
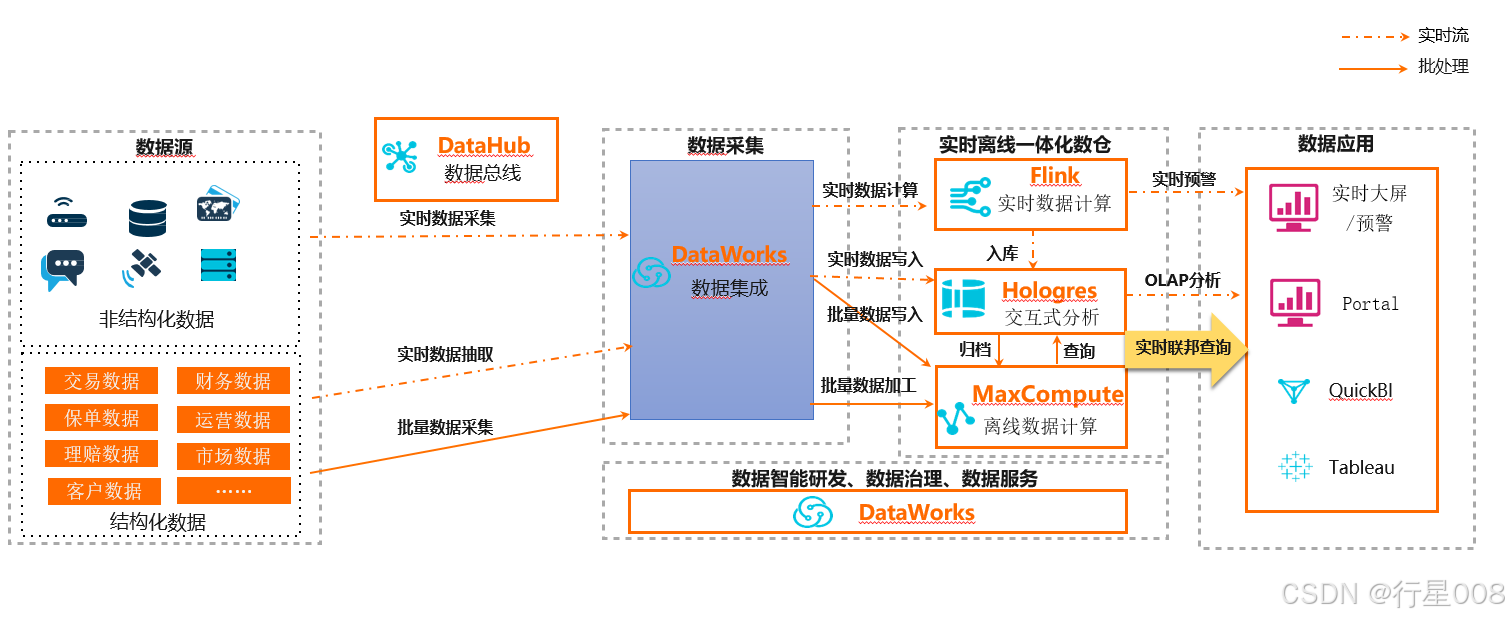
适用行业:适用于电商、游戏、社交等互联网行业大规模数据实时查询场景。
方案优势:
阿里云实时数仓全套链路与离线数仓无缝打通。
满足一套存储,两种计算(实时计算和离线计算)的高性价比组合。
产品组合:DataHub+实时计算Flink+交互式分析+MaxCompute+DataWorks+Quick BI / DataV
场景说明:
数据采集:通过DataWorks(批量)、DataHub(实时)进行统一数据采集接入。
数据开发:基于DataWorks进行数据全链路研发,包括数据集成、数据开发和ETL 、转换及计算等开发,以及数据作业的调度、监控、告警等。DataWorks提供数据开发链路的安全管控的能力,以及基于DataWorks数据服务模块提供统一数据服务API能力。
实时数据:按实际业务需求使用Flink进行实时ETL(可选)、结果入库,使用交互式分析产品构建实时数据仓库、应用集市,并提供海量数据的实时交互查询和分析。
交互式分析:提供实时离线联邦查询。历史离线数据存放于MaxCompute,实时分析数据存放于交互式分析。基于阿里云Quick BI或第三方数据分析工具(如Tableau)执行数据可视化,以及构建各业务板块数据服务门户应用。
通用数据开发
通常数据开发的总体流程包括数据产生、数据收集与存储、数据分析与处理、数据提取和数据展现与分享。
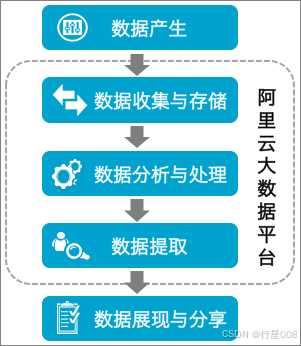
数据开发的流程如下所示:
- 数据产生:业务系统每天会产生大量结构化的数据,存储在业务系统所对应的数据库中,包括MySQL、Oracle和RDS等类型。
- 数据收集与存储:您需要同步不同业务系统的数据至MaxCompute中,方可通过MaxCompute的海量数据存储与处理能力分析已有的数据。
- DataWorks提供数据集成服务,可以支持多种数据源类型,根据预设的调度周期同步业务系统的数据至MaxCompute。
- 数据分析与处理:完成数据的同步后,可以对MaxCompute中的数据进行加工(MaxCompute SQL、MaxCompute MR)、分析与挖掘(数据分析、数据挖掘)等处理,从而发现其价值。
- 数据提取:分析与处理后的结果数据,需要同步导出至业务系统,以供业务人员使用其分析的价值。
- 数据展现与分享:数据提取成功后,可以通过报表、地理信息系统等多种展现方式,展示与分享大数据分析、处理后的成果。