一、什么是向量数据库
向量数据库(Vector Database),也叫矢量数据库,主要用来存储和处理向量数据。向量数据库的主要特点是高效存储与检索。利用索引技术和向量检索算法能实现高维大数据下的快速响应。
在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。两个向量的距离或者相似性可以通过余弦距离、欧式距离、汉明距离(为二进制向量时)等得到。
向量数据通常用于表示非结构化数据(如文本、图像、音频等)的特征。图像、文本和音视频这种非结构化数据都可以通过某种变换或者嵌入学习转化为向量数据存储到向量数据库中,从而实现对图像、文本和音视频的相似性搜索和检索。
向量数据库最初在传统人工智能(AI)和机器学习(ML)场景中已有应用,主要用于相似性搜索和推荐系统等任务。随着大语言模型(LLM)的兴起,由于模型存在token数量限制(通常仅能处理有限上下文),开发者开始广泛采用向量数据库来解决这一问题。具体做法是:将海量知识库(如文本、图像、音频等)通过嵌入(Embedding)算法或模型转换为高维向量。这些向量随后存储在专门的向量数据库(如Chroma、Milvus)中,这些数据库利用高效索引技术(如分层导航小世界HNSW或倒排文件IVF)来优化存储和检索。
当用户向大模型输入问题时,系统首先将问题本身通过相同的嵌入(Embedding)算法或模型转化为查询向量。接着,在向量数据库中执行近似最近邻(ANN)搜索,通过相似性度量(如余弦相似度或欧氏距离)计算匹配度,快速找出最相关的知识片段。这些匹配结果被组合成大模型的上下文输入,最终由大模型生成处理后的文本返回给用户。这种方法不仅显著降低了大模型的计算负担(减少重复推理),还提高了响应速度、降低了成本(避免频繁调用昂贵模型),并有效绕过了token限制,是一种高效的处理手段。
此外,向量数据库还在其他领域发挥关键作用,例如作为大模型的长期记忆存储系统(持久化保存对话历史和用户偏好),并在推荐系统、图像检索、自然语言处理(NLP)任务(如语义搜索和文档聚类)中提供不可替代的支持。例如,在电商平台中,向量数据库能基于用户行为向量实现个性化推荐;在安防领域,它支持人脸识别等实时分析。这些应用突显了其作为AI基础设施的核心价值。
向量数据库除了要管理向量数据外,还是支持对传统结构化数据的管理。实际使用时,有很多场景会同时对向量字段和结构化字段进行过滤检索。例如:实际使用时,向量数据库还可保存向量与元数据(描述向量来源或属性的结构化信息)的映射关系,即返回向量及元数据数据ID(映射字段),根据元数据ID获取信息并过滤。
向量数据库与传统数据库(如关系型数据库、键值存储)区别:
| 特性 | 向量数据库 | 传统数据库 |
|---|---|---|
| 数据类型 | 高维向量(连续数值) | 结构化数据(表、键值、文档等) |
| 查询方式 | 相似性搜索(基于距离或相似度) | 精确匹配(SQL、键值查询等) |
| 索引结构 | HNSW、IVF、ANNOY等(专为高维数据设计) | B+树、哈希表等(优化精确匹配查询) |
| 应用场景 | 语义搜索、推荐系统、图像检索(需处理高维向量数据的场景) | 事务处理、数据分析(更适用于结构化数据处理的场景) |
| 计算复杂度 | 较高(高维向量计算) | 较低(基于精确匹配) |
二、主流的向量数据库
选型建议
- 大规模分布式场景:选 Milvus(开源)或 Zilliz Cloud(商业)。
- 零运维需求:选 Pinecone(全托管商业服务)。
- 知识图谱/多模态:选 Weaviate(开源+商业)。
- 轻量级/边缘计算:选 Qdrant 或 Chroma。
- 已有PostgreSQL:用 Pgvector 扩展。
- 实时缓存+向量:选 RedisVL。
- 学术研究/底层优化:用 Faiss 库。
1. 开源向量数据库
| 数据库名称 | 核心特点 | 典型应用场景 | 备注 |
|---|---|---|---|
| Milvus | 分布式架构,支持多种索引(IVF_FLAT、HNSW、Annoy),高性能大规模向量检索,集成Faiss/HNSW等算法 | 大规模图像/视频检索、推荐系统、NLP语义搜索 | 社区活跃,商业版为Zilliz Cloud |
| Weaviate | 结合向量搜索与图数据库,内置NLP模块,支持混合搜索(关键词+向量) | 知识图谱、多模态搜索(文本+图像)、企业文档智能检索 | 开源版功能完整,提供商业托管 |
| Qdrant | Rust编写,内存占用低,支持地理位置过滤和稀疏/稠密向量 | LBS应用(附近地点推荐)、高并发小规模检索 | 开源版无功能阉割,有商业托管 |
| Chroma | 轻量级嵌入式设计,API简单,支持内存/文件/服务模式,集成LangChain | 小型AI项目原型开发、本地化语义搜索工具 | 底层基于SQLite,适合快速实验 |
| Pgvector | PostgreSQL扩展,支持HNSW/IVFFlat索引,直接结合SQL查询 | 已有PostgreSQL的业务升级、需事务+向量混合操作 | 降低架构复杂度,无需独立数据库 |
| Faiss | Meta开发的库(非数据库),极致优化的CPU/GPU加速,支持IVF/PQ等索引 | 学术研究、底层算法优化、与其他数据库(如ES)结合 | 需自行构建存储层,性能顶尖 |
2. 商业向量数据库
| 数据库名称 | 核心特点 | 典型应用场景 | 备注 |
|---|---|---|---|
| Pinecone | 全托管服务,零运维,低延迟动态更新,内置元数据过滤 | 生成式AI(如ChatGPT长期记忆)、实时推荐系统 | 开发者友好,快速API集成 |
| Zilliz Cloud | Milvus的商业托管版,增强企业支持与稳定性 | 同Milvus场景,需企业级服务 | 基于Milvus核心 |
| Qdrant Cloud | Qdrant的商业托管版本,云服务优化 | 同Qdrant场景,需托管服务 | 开源版基础上增强 |
| Vespa | Yahoo开发,支持搜索和推荐引擎,集成向量搜索 | 大规模实时推荐、混合检索场景 | 支持云和本地部署 |
3. 传统数据库的向量扩展
| 扩展名称 | 核心特点 | 典型应用场景 | 备注 |
|---|---|---|---|
| RedisVL | 基于Redis Stack,低延迟实时检索,复用Redis架构 | 缓存+向量混合场景(如会话式AI) | 需搭配RediSearch模块 |
| Elasticsearch | 支持dense_vector字段,8.0+版本集成HNSW索引 | 结合全文搜索与向量检索的混合系统 | 支持余弦/欧式距离 |
| Pgvector | 作为PostgreSQL扩展 | 同开源类 | 同开源类 |
三、向量数据库工作原理
从技术上来讲,要实现对非结构化数据的精确匹配是很困难的,因为数据没有结构,就不存在类似关系型数据库中的表定义,无法通过某个字段(属性)来查询。**可以将向量理解为原始非结构化数据的一个标识,任何一个非结构化数据经过某种Embedding算法后,都能转换成一个向量,找到向量就能找到对应的原始数据。**在查询时,首先将待查询的条件进行Embedding,查询条件就转换成了一个向量。然后比较条件向量和数据库中存在的原始数据向量,返回最相似的N个原始数据向量,进而得到N个原始数据的查询结果。
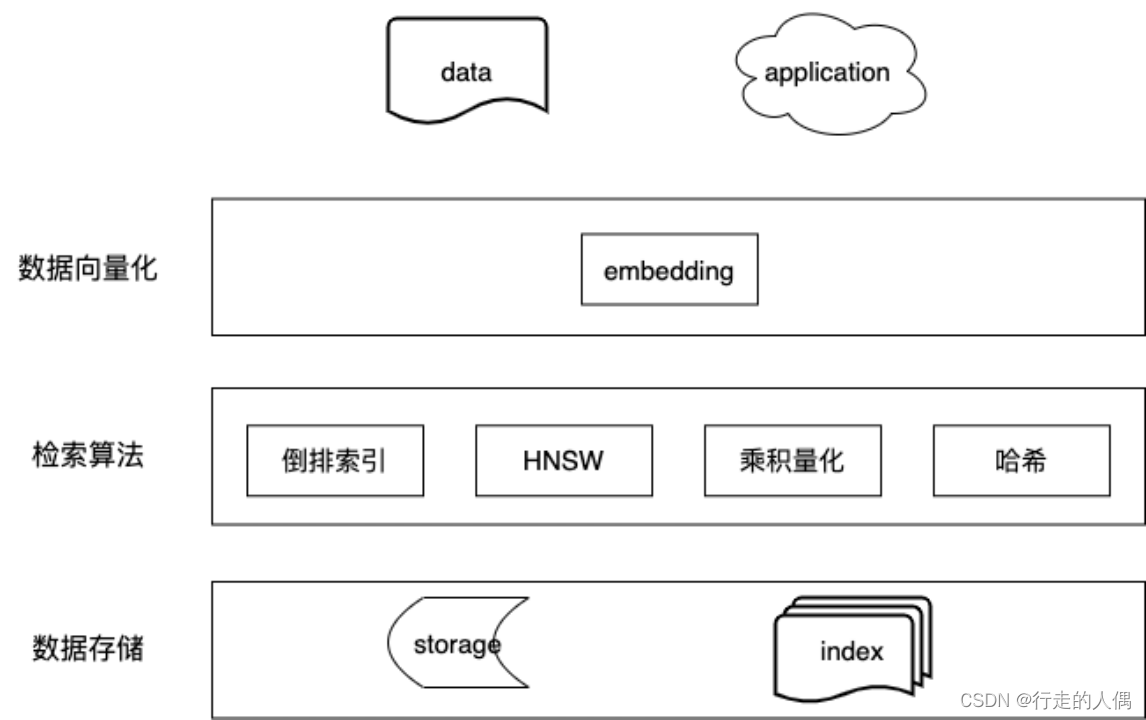
1. 向量生成
Embedding又叫嵌入,用于将复杂的非结构化数据表示为向量,以便在向量数据库中存储以及实现对非结构化数据的相似性判断。
不同结构数据的Embedding算法和模型都有哪些?
文本嵌入
- Word2Vec:根据语料库中的上下文将单词转换为向量。
- GloVe(全局向量表示):使用词共现统计生成嵌入。
- FastText:通过考虑子词信息扩展Word2Vec。
- BERT(双向编码器表示):为句子和单词生成上下文感知的嵌入。
- GPT(生成预训练变换器):提供嵌入作为其语言建模能力的一部分。
- Sentence Transformers:专为句子级别嵌入设计。
图像嵌入
- 卷积神经网络(CNNs):从图像中提取特征,用于分类和识别任务。
- ResNet、VGG、Inception:用于生成图像嵌入的预训练CNN模型。
- 视觉变换器(ViT):将变换器架构应用于图像数据。
视频嵌入
3D卷积网络:通过考虑时间信息扩展CNN以处理视频数据。
循环神经网络(RNNs)/ LSTMs:处理视频帧序列。
I3D(膨胀3D卷积网络):用于视频动作识别。
音频嵌入
- MFCC(梅尔频率倒谱系数):传统的音频特征提取方法。
- 基于频谱图的CNNs:使用频谱图作为输入的CNN模型。
- WaveNet:用于生成音频嵌入的深度神经网络架构。
- OpenAI的Whisper:用于语音识别和嵌入的模型。
以上这些算法和模型需要根据具体需求进行选择。
2. 向量检索
怎样从大量的向量中找到(与查询向量)最相似的N个向量?
2.1 相似度计算
怎么判断两个向量最相似?向量的距离可以用来衡量两个向量的相似度,常见的有余弦距离,欧式距离和向量内积几种方式。
- 余弦距离:通过计算两个向量的夹角余弦值来计算相似性。夹角为0时相似度为1,夹角90度时,相似度为0,夹角180时相似度为-1,因此余弦相似度的取值范围为[-1,1]。
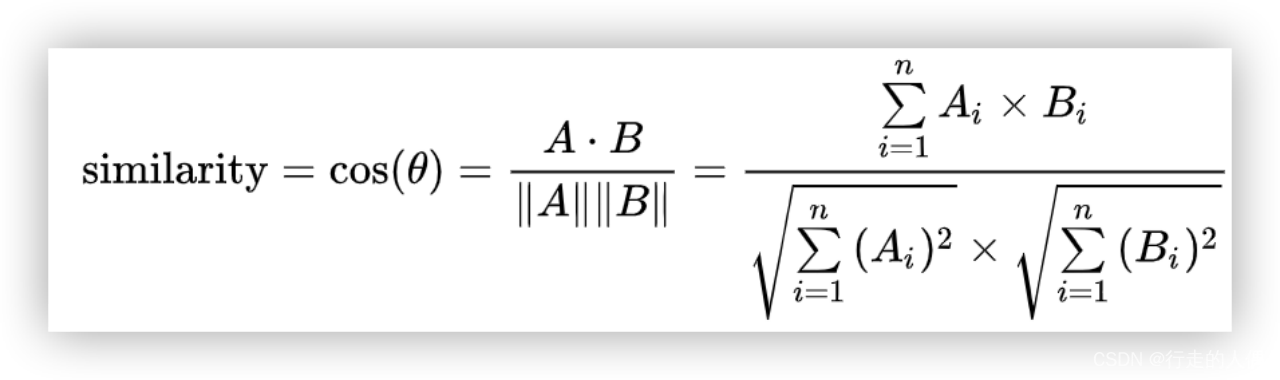
- 欧式距离:全称是欧几里得距离,度量的是空间上两个点之间的连线距离,空间上的点都可以看着是从原点出发的向量。

向量内积:又称数量积,是指接受在实数R上的两个向量并返回一个实数值标量的二元运算。
两个向量a = [a1, a2,…, an]和b = [b1, b2,…, bn]的点积定义为:a·b=a1b1+a2b2+……+anbn。
2.2 索引构建算法
输入一个向量,从向量数据库中查找与输入向量最相似的top N个向量返回。
若不采用任何算法进行索引,需要遍历数据库中所有的数据,计算查询向量与库中向量的相似性,之后按照相似度倒序返回top N条。这种方式一般也称着暴力检索,召回率和准确率都是最高的,但是在数据量大的情况下遍历计算相似度是非常耗时的,需要一些策略算法进行优化:在召回率,内存占用和响应时间之间权衡。
通过预先的索引构建,尽可能减小查询时的搜索空间,加快检索速度。组织和索引嵌入后的向量是向量数据库和相似性搜索系统的核心任务。类似MySQL中的B+ tree,为了高效地存储和检索向量数据库中向量,通常会使用专门的算法,目前主要的几种检索算法有:基于树的方法、基于图的方法,基于乘积量化的方法,基于哈希的方法、基于倒排索引的方法。
| 算法类型 | 代表算法 | 核心思想 | 核心优势 | 典型缺点 |
|---|---|---|---|---|
| 基于树 | KD-Tree, Annoy | 通过递归划分数据空间减少搜索范围,类似二叉查找树。 | 结构简单,低维数据高效 | 高维性能骤降 |
| 基于图 | HNSW | 利用邻居节点的连通性构建"高速公路",快速缩小搜索范围。 | 检索极快,召回率高 | 内存占用大 |
| 基于量化 | PQ | 通过量化技术压缩向量,减少计算量和存储成本。 | 存储压缩,计算高效 | 精度损失 |
| 基于哈希 | LSH | 利用局部敏感哈希(LSH)将相似向量映射到相同桶。 | 分桶检索快 | 召回率低 |
| 基于倒排索引 | IVFPQ | 结合聚类与倒排索引,先定位子空间再精确搜索。 | 规模扩展性好,效率平衡 | 需调参(聚类数、量化段) |
- 实际应用中,HNSW(单机)和 IVFPQ(分布式)是当前主流方案,结合GPU加速可进一步提升性能。
3. 向量存储
向量数据库除了要管理向量数据外,还是支持对传统结构化数据的管理。向量数据库将高维向量存储在专门的数据结构中,并与元数据关联。
例如:向量:[0.1, -0.3, 0.5, ...]、元数据:{ "text": "这是一只猫", "id": 123, "timestamp": "2025-04-21" }
具体理解:
高维向量是对文本、图像等非结构化数据的数学表示。例如,一段文本可能被转换为768维的浮点数数组,每个维度捕捉语义或语法特征。
专门的数据结构(如HNSW、KD树、倒排索引)通过空间分割或图结构优化相似性搜索,避免与所有向量逐一比对,提升检索效率。
元数据关联的意义与实现
元数据:是描述向量来源或属性的结构化信息,例如:文本向量的来源文档ID、发布时间、作者;图像向量的文件路径、拍摄设备。
关联方式:
- 内嵌存储:向量库(如Milvus)直接存储元数据字段(如
tag),与向量同记录。 - 分离存储:向量存向量库(如FAISS),元数据存关系库(如PostgreSQL),通过唯一ID(如
doc_id)关联。
- 内嵌存储:向量库(如Milvus)直接存储元数据字段(如
应用价值:
- 精准过滤:先按元数据(如时间范围、权限)筛选,再执行向量搜索,提升效率与安全性。
- 可解释性:通过元数据追溯结果来源(如医疗报告中定位到具体文献)。
协同工作示例:
向量数据库通过专用数据结构解决高维向量的高效检索问题,再通过元数据关联扩展应用场景(如权限控制、多模态管理),二者结合使非结构化数据的语义搜索兼具性能与实用性。