并发编程:原子性、可见性、有序性
目录
参考:
# 并发编程:原子性、可见性、有序性
**可见性、原子性、有序性是并发编程中经常提到的名词,如果能保证这三个条件,我们的程序就是线程安全的。**反之,则会存在各种诡异的BUG。
**为什么会有并发编程?**核心问题在于CPU、内存、I/O设备速度的差异,而为了平衡三者的速度差异,计算机体系结构、操作系统、编译程序做出了这些贡献:
操作系统增加了进程、线程来分时复用CPU。解决CPU与I/O设备的速度差异。
CPU增加了缓存。解决CPU与内存速度差异。
编译程序优化指令执行次序。这样可以更有效地利用缓存。
这三点提高了系统性能,同时也造成了原子性、可见性、有序性三个问题。
# 起因:计算机效率和性能的优化
计算机的效率和性能优化:CPU运算速度和IO速度的不平衡,导致CPU的资源无法合理的运用起来,分别从任务切换、多级缓存、指令重排几个方向进行优化。
如何最大化的利用CPU?CPU运算速度和IO速度的不平衡一直是计算机优化的一个课题,我们都知道CPU运算速度要以百倍千倍程度快于IO的速度,而在进行任务的执行的时候往往都会需要进行数据的IO,正因为这种速度上的差异,所以当CPU和IO一起协作的时候就产生问题了,CPU执行速度非常快,一个任务执行时候大部分时间都是在等待IO工作完成,在等待IO的过程中CPU是无法进行其它工作的,所以这样就使得CPU的资源根本无法合理的运用起来。
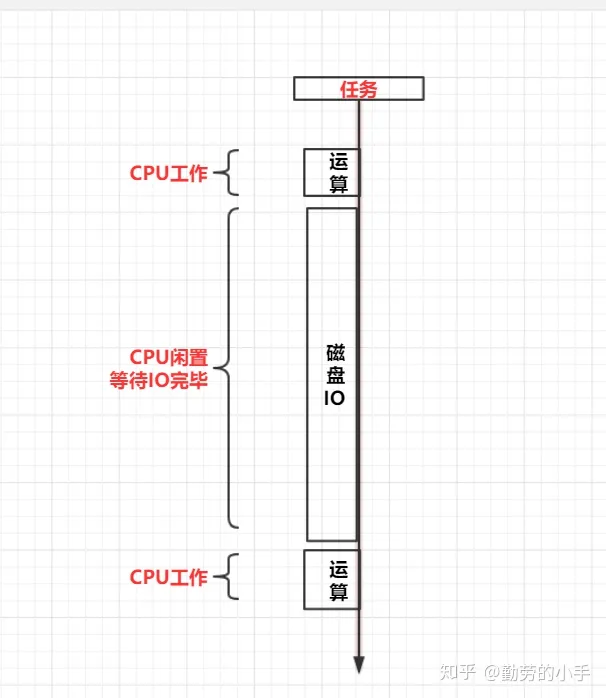
CPU就相当于我们计算机的大脑,如何把CPU资源合理的利用起来就直接关系到我们计算机的效率和性能,所以为了这个课题计算机分别从任务切换、多级缓存、指令重排这几个方向进行了优化,但这几个方向也是并发问题的根本来源 。
# 并发问题根源之一:任务切换导致的原子性问题
# 进程和线程的产生
在最原始的系统里计算机内存中只能允许运行一个程序,这个时候的CPU的能力完全是过剩的,因为CPU在接收到一个任务之后绝大部分时间都是处在IO等待中,CPU根本就利用不起来,所以这个时候就需要一种同时运行多个程序的方法,这样的话当CPU执行一个任务IO等待的时候可以切换到另外一个任务上去执行指令,不必在IO上浪费时间,那么CPU就能很大程度的利用起来,所以基于这种思路就产生了进程和线程。
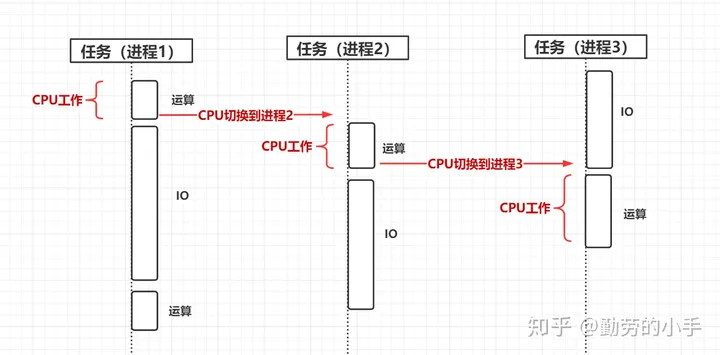
有了进程后,一个内存可以划分出不同的内存区域分别由多个进程管理,当一个进程IO阻塞的时候可以切换到另外一个进程执行指令,为了合理公平的把CPU分配到各个进程,CPU把自己的时间分为若干个单位的片段,每在一个进程上执行完一个单位的时间就切换到另外一个进程上去执行指令,这就是CPU的时间片概念。有了进程后我们的电脑就可以同时运行多个程序了,我们可以一边看着电影一边聊天,在CPU的利用率又进一步提升了CPU的利用率。
因为进程做任务切换需要切换内存映射地址,而一个进程创建的所有线程,都是共享一个内存空间的,所以线程做任务切换成本就很低了,现代的操作系统都基于更轻量的线程来调度,现在我们提到的“任务切换”都是指“线程切换”。
# CPU切换线程执导致的原子性问题
原子性:是指把一个操作或者多个操作视为一个整体,在执行的过程不能被中断的特性叫原子性。
因为IO、内存、CPU缓存他们的操作速度有着巨大的差距,假如CPU需要把CPU缓存里的一个变量写入到磁盘里面,CPU可以马上发出一条对应的指令,但是指令发出后的很长时间CPU都在等待IO的结束,而在这个等待的过程中CPU是空闲的。
所以为了提升CPU的利用率,操作系统就有了进程和时间片的概念,同一个进程里的所有线程都共享一个内存空间,CPU每执行一个时间段就会切换到另外一个进程处理指令,而这执行的时间长度是以时间片(比如每个时间片为1毫秒)为单位的,通过这种方式让CPU切换着不同的进程执行,让CPU更好的利用起来,同时也让我们不同的进程可以同时运行,我们可以一边操作word文档,一边用QQ聊天。
后来操作系统又在CPU切换进程执行的基础上做了进一步的优化,以更细的维度“线程”来切换任务执行,更加提高了CPU的利用率。但正是这种CPU可以在不同线程中切换执行的方式会使得我们程序执行的过程中产生原子性问题。
示例
Int number = 0; //语句1
number = number + 1; //语句2
2
在执行语句2的时候,我们的直觉number = number + 1 是一个不可分割的整体,但是实际CPU操作过程中并非如此,我们的编译器会把number = number + 1 拆分成多个指令交给CPU执行,指令可能如下:
指令1:CPU把number从内存拷贝到CPU缓存。
指令2:把number进行+1的操作。
指令3:把number回写到内存。
2
3
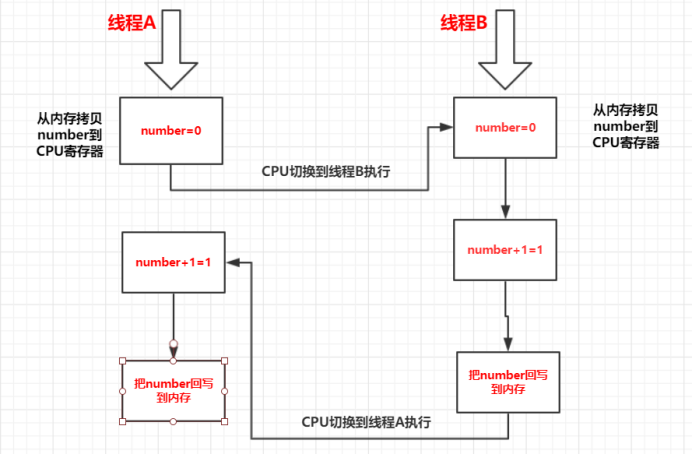
在这个时候如果有多线程同时去操作number变量,就很有可能出现问题,因为CPU会在执行上面任何一个指令的时候切换线程执行指令,这个时候就可能出现执行结果与我们预期结果不符合的情况。比如如果现在有两个线程都在执行number = number + 1,结果CPU执行流程可能会如下:
执行细节:
1、CPU先执行线程A的执行,把number=0拷贝到CUP寄存器。
2、然后CPU切换到线程B执行指令。
3、线程B 把number=0拷贝到CUP寄存器。
4、线程B 执行number=number+1 操作得到number=1。
5、线程B把number执行结果回写到缓存里面。
6、然后CPU切换到线程A执行指令。
7、线程A执行number=number+1 操作得到numbe=1。
8、线程A把number执行结果回写到缓存里面。
9、最后内存里面number的值为1。
2
3
4
5
6
7
8
9
# 并发问题根源之二:缓存导致的可见性问题
# 高速缓存的产生
为了减少CPU等待IO的时间,让昂贵的CPU资源充分利用起来,提升计算机效率,其中一个思路就是减少IO等待的时间,所以就在CPU的基础上CPU级别的缓存(L1,L2,L3 缓存)。
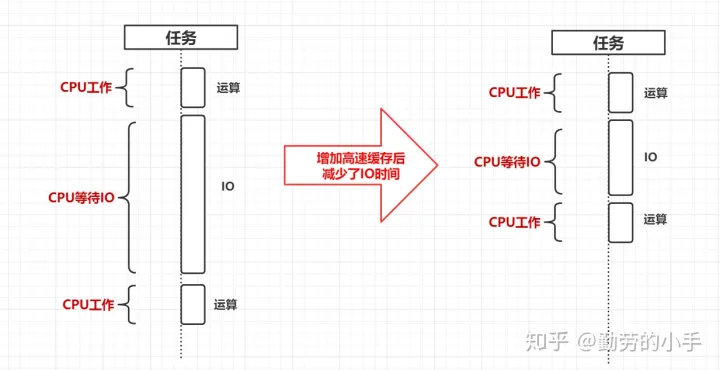
在计算机系统中,CPU高速缓存是用于减少处理器访问内存所需的时间,其容量远小于内存,但其访问速度却是内存IO的几十上百倍。当处理器发出内存访问请求时,会先查看高速缓存内是否有请求数据。如果存在(命中),则不需要访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
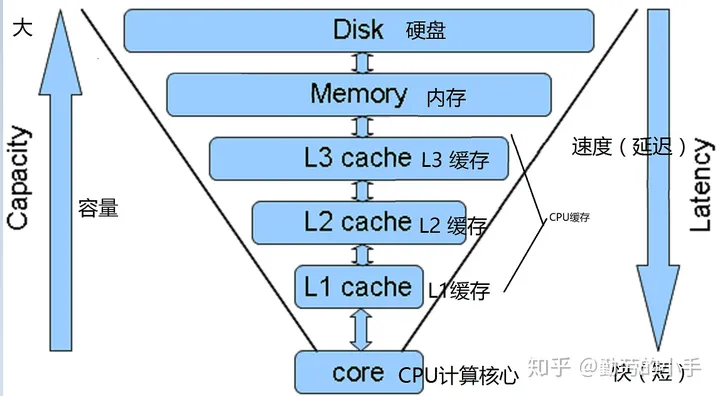
# 缓存导致的可见性问题
可见性:当一个线程修改共享变量的值,其他线程能够立即知道被修改了。
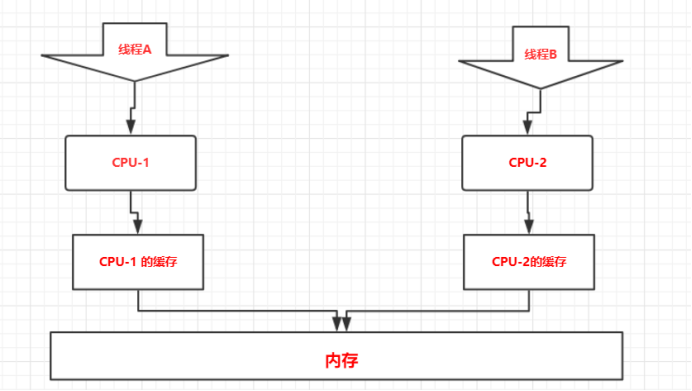
在有了高速缓存之后,CPU的执行操作数据的过程会是这样的,CPU首先会从内存把数据拷贝到CPU缓存区。然后CPU再对缓存里面的数据进行更新等操作,最后CPU把缓存区里面的数据更新到内存。 磁盘、内存、CPU缓存会按如下形式协作:
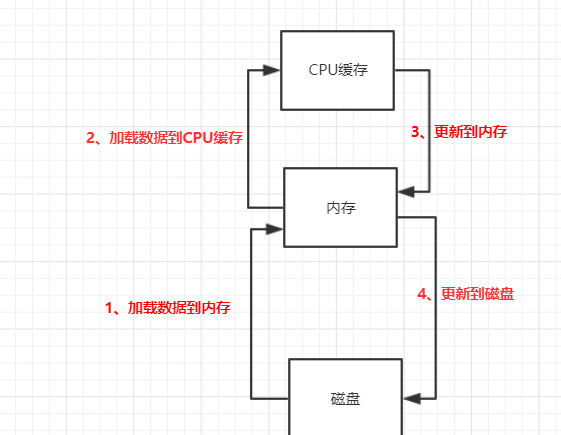
缓存导致的可见性问题就是指我们在操作CPU缓存过程中,由于多个CPU缓存之间独立不可见的特性,导致共享变量的操作结果无法预期。
在单核CPU时代,因为只有一个核心控制器,所以只会有一个CPU缓存区,这时各个线程访问的CPU缓存也都是同一个,在这种情况一个线程把共享变量更新到CPU缓存后另外一个线程是可以马上看见的,因为他们操作的是同一个缓存,所以他们操作后的结果不存在可见性问题。
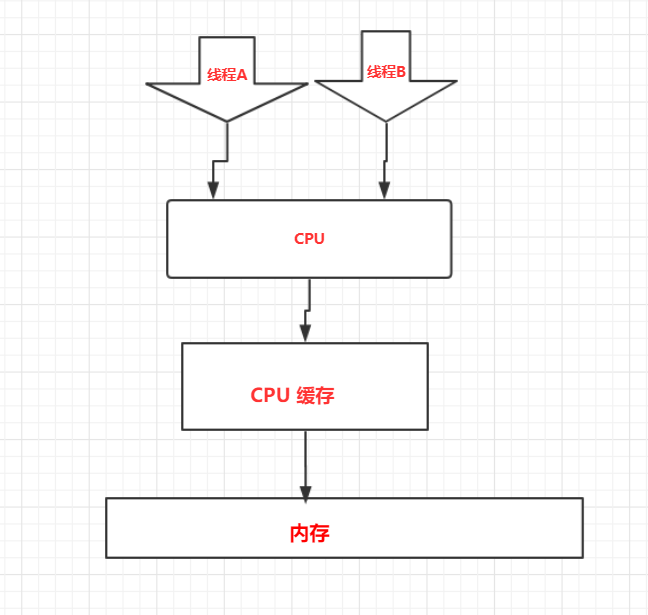
而随着CPU的发展,CPU逐渐发展成了多核,CPU可以同时使用多个核心控制器执行线程任务,当然CPU处理同时处理线程任务的速度也越来越快了,但随之也产生了一个问题,多核CPU每个核心控制器工作的时候都会有自己独立的CPU缓存,每个核心控制器都执行任务的时候都是操作的自己的CPU缓存,CPU1与CPU2它们之间的缓存是相互不可见的。这种情况下多个线程操作共享变量就因为缓存不可见而带来问题,多线程的情况下线程并不一定是在同一个CUP上执行,它们如果同时操作一个共享变量,但因为在不同的CPU执行所以他们只能查看和更新自己CPU缓存里的变量值,线程各自的执行结果对于别的线程来说是不可见的,所以在并发的情况下会因为这种缓存不可见的情况会导致问题出现。
示例
public class JMMDemo {
int value = 0;
void add() {
value++;
}
public static void main(String[] args) throws Exception {
final int count = 100000;
final JMMDemo demo = new JMMDemo();
Thread t1 = new Thread(() -> IntStream.range(0, count).forEach((i) -> demo.add()));
Thread t2 = new Thread(() -> IntStream.range(0, count).forEach((i) -> demo.add()));
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(demo.value);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
两个线程同时调用add() 方法对value属性进行+1 ,循环10W次,等两个线程执行结束后,我们的预期结果value的值应该是20W,可是我们在多核CPU的环境下执行结果并非我们预期的值。

使用 javap 命令看一下字节码:
void add();
descriptor: ()V
flags:
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: dup
2: getfield #2 // Field value:I
5: iconst_1
6: iadd
7: putfield #2 // Field value:I
10: return
LineNumberTable:
line 9: 0
line 10: 10
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
着重看一下 add 方法,可以看到一个简单的 i++ 操作,有很多的字节码,而它们都是按照顺序执行的。当它自己执行的时候不会有什么问题,但是如果放在多线程环境中,执行顺序就变得不可预料了。
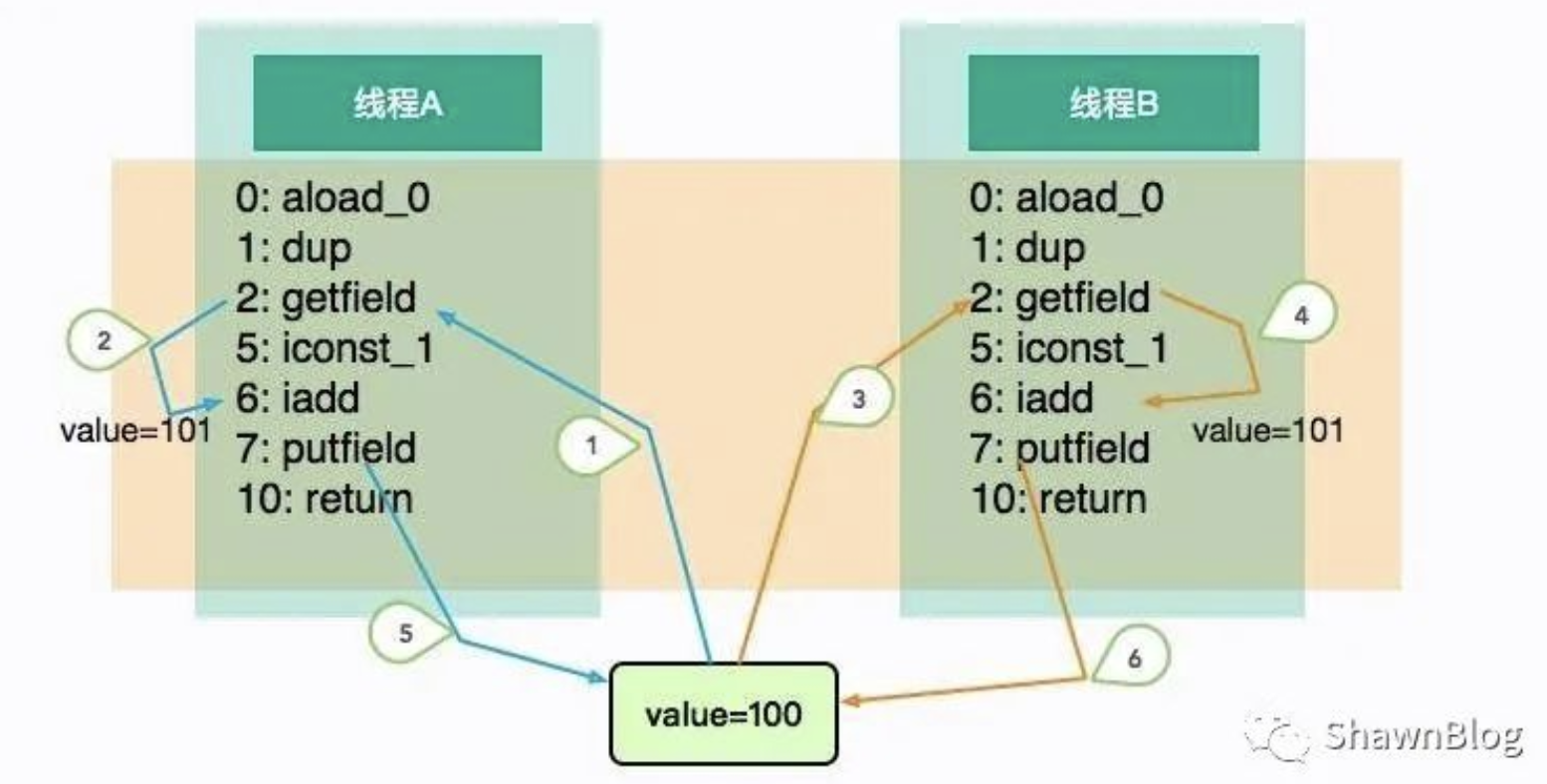
线程 A 和 B 并发执行相同的代码块 add,执行的顺序如图中的标号,它们在线程中是有序的(1、2、5 或者 3、4、6),但整体顺序是不可预测的。线程 A 和 B 各自执行了add 操作,线程 A 和 B 修改了value值是无法彼此立即知晓的,putfield 指令直接覆盖了内存中的值,最终执行结果并非我们预期的值。
# 并发问题根源之三:指令重排导致的有序性问题
# 指令优化(指令重排)
进程和线程本质上是增加并行的任务数量来提升CPU的利用率,缓存是通过把IO时间减少来提升CPU的利用率,而指令顺序优化的初衷就是想通过调整CPU指令的执行顺序和异步化的操作来提升CPU执行指令任务的效率。
指令顺序优化可能发生在编译、CPU指令执行、缓存优化几个阶段,其优化原则就是只要能保证重排序后不影响单线程的运行结果,那么就允许指令重排序的发生。其重排序的大体逻辑就是优先把CPU比较耗时的指令放到最先执行,然后在这些指令执行的空余时间来执行其他指令,就像我们做菜的时候会把熟的最慢的菜最先开始煮,然后在这个菜熟的时间段去做其它的菜,通过这种方式减少CPU的等待,更好的利用CPU的资源。
# CPU和编译器的指令重排导致的有序性问题
在编写代码的顺序结构中,我们可以直观的指定代码的执行顺序, 即从上到下按序执行。但CPU为了提高程序的运行效率,提高并行效率,可能会对代码进行乱序优化,编译器也会根据自己的决策,对代码的执行顺序进行重新排序,优化指令的执行顺序,因为编译器认为,重排序后的代码执行效率更优,可以提升程序的性能和执行速度。这样一来,代码的执行顺序就未必是编写代码时候的顺序了,在单线程情况下,最终结果看起来没什么变化,但在多线程的情况下就可能会出错。
示例
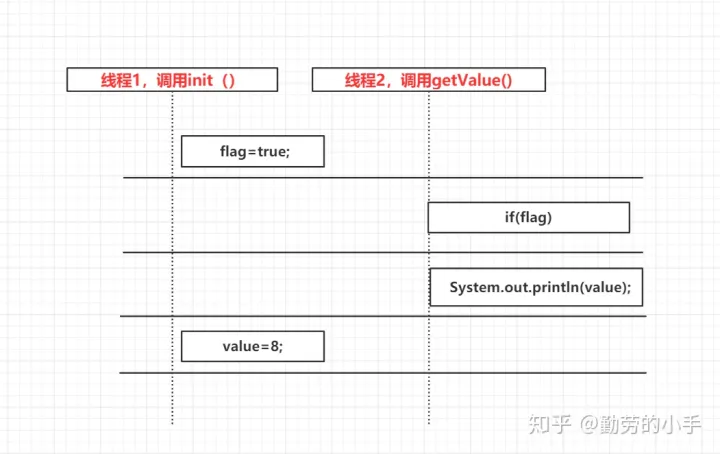
下面的程序代码如果init()方法的代码经过了指令重排序后,两个方法在两个不同的线程里面调用就可能出现问题。
private static int value;
private static boolean flag;
public static void init(){
value=8; //语句1
flag=true; //语句2
}
public static void getValue(){
if(flag){
System.out.println(value);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
根据上面代码,如果程序代码运行都是按顺序的,那么getValue() 中打印的value值必定是等于8的,不过如果init()方法经过了指令重排序,那么结果就不一定了。根据重排序原则,init()方法进行指令重排序后并不会影响其运行结果,因为语句1和语句2之间没有依赖关系。 所以进行重排序后代码执行顺序可能如下。
flag=true; //语句2
value=8; //语句1
2
如果init()方法经过了指令重排序后,这个时候两个线程分别调用 init()和getValue()方法,那么就有可能出现下图的情况,导致最终打印出来的value数据等于0。